Трохи історії
Якщо ви ще не дивилися фільм «Гра в імітацію» (2014) з Бенедиктом Камбербетчем в головній ролі, то обов’язково зробіть це. Адже цей фільм — про британського математика Алана Тюрінга, з якого починається історія створення штучного інтелекту.
У 1935 році Тюрінг описав абстрактну обчислювальну машину, що складається з безмежної пам’яті та сканера, який переміщується вперед і назад по пам’яті, символ за символом, зчитуючи знайдене та записуючи подальші символи. Фактично машина Тюрінга була прототипом комп’ютера. У найстарішій універсальній англомовній енциклопедії Британіці (Britannica) припускається, що математик виголосив найпершу публічну лекцію (Лондон, 1947), у якій згадував комп’ютерний інтелект. «Нам потрібна машина, яка може навчатися на досвіді», — сказав він. У 1948 році Тюрінг представив концепцію штучного інтелекту у праці під назвою «Інтелектуальні машини». Саме Тюрінгу належить ідея гри в шахи з комп’ютером. Згодом цей метод застосовуватимуть багато разів, щоб перевірити «інтелект» машини.

А в 1950 році у статті «Обчислювальні машини та розум» Тюрінг публікує ідею тесту, який мав перевірити здатність машини мислити, як людина. Для цього тесту потрібен суддя, людина і машина. Всі учасники тесту не повинні бачити одне одного. На підставі відповідей на запитання суддя повинен визначити, з ким він розмовляє: з людиною чи з комп’ютерною програмою. Завдання комп’ютерної програми — ввести суддю в оману, змусивши зробити неправильний вибір. Якщо суддя не може сказати точно, хто зі співрозмовників є людиною, то вважається, що машина пройшла тест. Проте сьогодні тест вважається дещо застарілим.

Над різними аспектами штучного інтелекту, починаючи з 1950-х років і завершуючи сьогоднішнім днем, працювало багато різних учених. Але основні розробки відбувалися в Сполучених Штатах Америки. «Найкращі дослідники країни працювали в Кремнієвій долині в умовах щедрого фінансування, унікальної культури й підтримки впливових компаній», — писав визнаний експерт у сфері ШІ Кай-Фу Лі у книжці «AI наддержави штучного інтелекту: Китай, Кремнієва долина і новий світовий лад».
Дослідники розділилися на дві течії: одну представляли прихильники «символічних або експертних систем» на основі правил, іншу — прихильники принципу нейронних мереж. Перший підхід полягав у тому, щоб навчити комп’ютери мислити на основі закодованих правил («якщо… то…»), але він переставав працювати, коли треба було розглянути велику кількість (чи безліч) варіантів. Вчені другого табору поставили перед собою завдання імітувати людський мозок, коли штучні нейрони передають та отримують інформацію подібно до нейронів людини. У цьому випадку науковці не задавали машині жодних правил, навпаки, вводили велику кількість прикладів і на основі цього масиву даних дозволяли самій визначити закономірності.
Якщо усі ці дослідження залишалися непомітними для пересічних людей у різних країнах, то світова література чи кінематограф оприявнювали те, що було за дверима дослідницьких лабораторій. Американський Термінатор і радянський Електронік — яскраві представники тієї епохи розвитку ШІ. Але, мабуть, ніхто тоді на піку популярності цих фільмів не міг подумати, що ще стане свідком епохальних змін в історії розвитку людства в реальному житті.

Починаючи із середини XX століття було кілька хвиль розвитку ШІ, які змінювалися періодами стагнації (їх називали «зимами ШІ»).
Коли у 2022 році провідна американська компанія та дослідницька лабораторія у сфері штучного інтелекту OpenAI (заснована у 2015 році) відкрила для загального користування ChatGPT, до нього поставились як до іграшки. Але минуло зовсім мало часу — і стало зрозуміло: ця технологія повністю змінить життя людей. За перші п’ять днів існування ChatGPT здобув один мільйон користувачів, а за перші два місяці — 100 мільйонів. Станом на початок 2026 року кількість активних користувачів ChatGPT досягла 900 мільйонів/щотижня.
Поява цієї генеративної мовної моделі фактично прискорила бум штучного інтелекту. Компанії, які працювали у сфері ШІ-розробок, відкрили для масової аудиторії велику кількість ШІ-інструментів, якими можна користуватися як у повсякденні, так і в різних професійних сферах. Про ці інструменти йтиметься в наступних Темах.
Розвиток ШІ у датах
1935 — Алан Тюрінг винаходить обчислювальну машину Enigma, яка стала прототипом першого комп’ютера.
1943 — нейрофізіолог Воррен Маккалох з Іллінойського університету та математик Волтер Піттс з Чиказького університету опублікували дослідження про нейронні мережі та автомати, згідно з яким кожен нейрон у мозку є простим цифровим процесором, а мозок в цілому — формою обчислювальної машини.
1950 — Алан Тюрінг розробив тест для перевірки здатності комп’ютера імітувати людське мислення.
1954 — запущена перша штучна нейронна мережа.
1956 — американський інформатик та дослідник мислення Джон Маккарті вперше вживає термін «штучний інтелект».
1960 — створено мову програмування LISP (List Processor), яка протягом десятиліть була основною мовою для роботи зі штучним інтелектом у США, перш ніж її витіснили у 21 столітті такі мови як Python, Java та C++.
1966 — відбувся перший «діалог» між двома запрограмованими програмами «Елізою» та «Перрі».
1968-72 — розроблений перший мобільний робот.
1972 — у Стенфордському університеті (США) розпочалась робота над MYCIN — програмою для діагностування інфекцій крові на основі зареєстрованих симптомів та результатів медичних аналізів.
1997 — Deep Blue, шаховий комп’ютер, побудований IBM, переміг чинного чемпіона світу Гаррі Каспарова у матчі з шести партій.
2010 — запущено перший віртуальний помічник Siri, який можна завантажити на смартфон.
2015 — безпілотний автомобіль Google Waymo (над яким компанія працювала з 2009 року) здійснив свою першу повністю безпілотну поїздку з одним пасажиром.
2022 — поява великої мовної моделі ChatGPT від OpenAI.
2023 — Microsoft додає чат-бота Copilot до своєї операційної системи Windows 11, пошукової системи Bing та браузера Edge; Google запускає Bard (сьогодні це Gemini).
Дані як паливо для ШІ
Основою створення та ефективної роботи будь-якого ШІ-інструмента є дані. Чим більше даних, тим краще. «У наш час для створення ефективних алгоритмів штучного інтелекту потрібні три складові: значні дані, обчислювальні потужності й праця компетентних, але не конче видатних розробників алгоритмів штучного інтелекту», — пише Кай-Фу Лі у книзі «АІ наддержави штучного інтелекту: Китай, Кремнієва долина і новий світовий лад».
Саме тому дані стають цінною валютою в еру штучного інтелекту. У Темі 2 ми поговоримо і про етику, і про правові аспекти функціонування ШІ, зокрема й про захист даних та авторські права на контент (адже компанії-розробники ШІ користуються цими даними та контентом без дозволу та безплатно). А поки що — про цінність даних.
Чому дані такі важливі та цінні для усіх інструментів ШІ й чому кажуть, що ШІ навчається на даних? Як це працює?
Вище ми вже згадували про два підходи до розробок у сфері ШІ. Отже, другий підхід, який будувався на імітації роботи людського мозку та безлічі нейронів, згодом отримав назву «глибинне навчання». Система має отримати якнайбільше даних, щоб мати можливість виявити ті чи інші закономірності й кореляції (взаємозв’язки), що пов’язують безліч точок цих даних із бажаним результатом (запитом). Для людей, які користуються ChatGPT чи іншими системами, цей процес є невидимим, вони отримують уже готову відповідь/рішення. Проте для цього системі потрібен великий масив даних і правильно сформульоване завдання. Наприклад, для навчання ChatGPT було використано приблизно 300 млрд слів (це мільйони книг та тисячі вебсайтів).

Відповідно у світі зростає конкуренція за доступ до даних, а також країни конкурують кількістю центрів обробки даних (або дата-центрів — спеціалізованих приміщень для розміщення та обслуговування серверного, мережевого обладнання та систем зберігання інформації; ці центри забезпечують роботу всього інтернету у світі, відповідно й ШІ також — ред.) та новими розробками в цій царині.
За прогнозами однієї з найбільших консалтингових фірм у світі McKinsey, до 2030 року застосування штучного інтелекту на основі даних генеруватиме 13 трильйонів доларів нової глобальної економічної активності. Це, кажуть експерти McKinsey, може визначити наступний світовий порядок, подібно до того, як видобуток нафти вплинув на розвиток економік різних країн у минулих століттях.
Сполучені Штати поки що залишаються світовим лідером у сфері даних: як у їхньому накопиченні, так і в обробці. У США розташовано 5427 центрів обробки даних, що більш ніж у десять разів перевищує показники будь-якої іншої країни, і вони споживають більше енергії, ніж будь-який інший регіон, йдеться у звіті про Індекс штучного інтелекту за 2026 рік від Стенфордського університету.
У 2026 році, за даними глобальної платформи Cloudscene, десятка країн з найбільшою кількістю центрів обробки даних виглядає так:
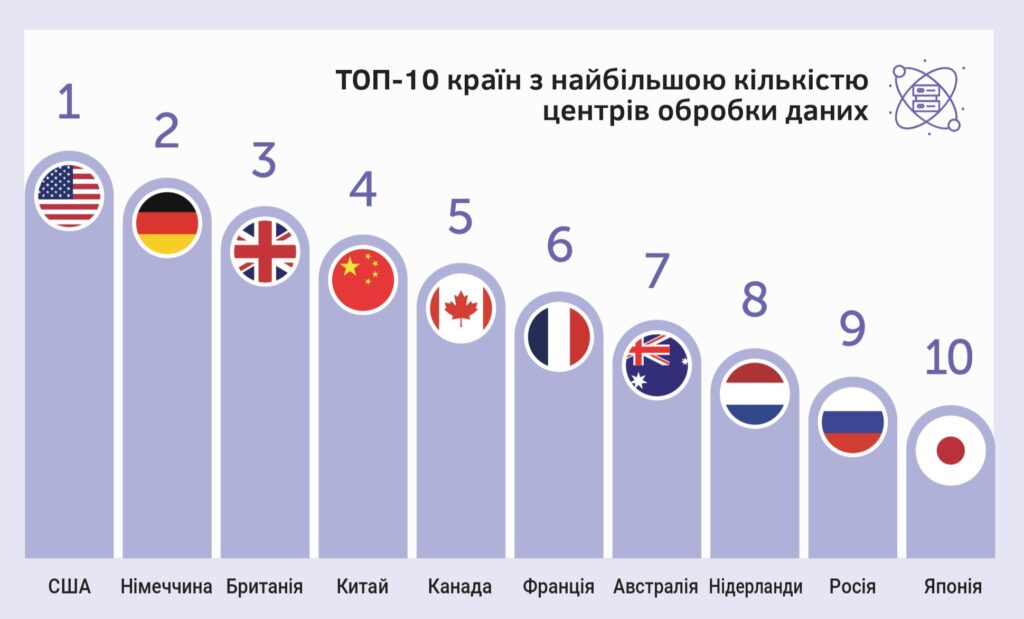
Як зазначають автори видання Economy Insights, «рейтинг країн з найбільшою кількістю центрів обробки даних — це не просто історія технологій. Це також історія географії, енергетики, нерухомості та національної конкурентоспроможності. Країни з щільними мережами центрів обробки даних, як правило, мають великі цифрові економіки, високий попит з боку підприємств, великі хмарні регіони, високий рівень інтернет-обміну, надійні системи електропостачання та великі пули корпоративних клієнтів».
Але варто враховувати, що будь-які рейтинги не є сталими через динамічний розвиток сфери та постійні зміни, які в ній відбуваються.
Штучний інтелект — це технологія, яка вже змінює і ще змінюватиме практично усі сфери життя. Стенфордський університет, який робить щорічний Індекс ШІ, у своєму звіті за 2026 рік зазначив, що розвиток ШІ прискорюється й охоплює дедалі більше людей. З’явилися моделі ШІ, які за усіма показниками перевищують базовий рівень знань людини рівня доктора філософії. А рівень впровадження інструментів ШІ в організаціях у світі досяг 88%. Також 4 із 5 студентів університетів зараз використовують генеративний ШІ. І це не межа можливостей. Трансформації триватимуть.

Як змінюється світ під впливом технологій та ШІ, гарно описав у своїй книзі «Nexus. Коротка історія інформаційних мереж від кам’яного віку до ШІ» Ювал Ной Харарі. У розвитку штучного інтелекту Харарі вбачає небезпеку людству. Він застерігає, що ця технологія може породити нові конфлікти між державами, які використовуватимуть дедалі руйнівнішу зброю на основі ШІ. Окрім того, автор припускає, що розвиток ШІ може призвести до тих апокаліптичних сценаріїв, які раніше можна було прочитати лише у книгах наукової фантастики — про панування алгоритмів над людиною. Харарі вважає, що людство незабаром зіштовхнеться із «загрозою тоталітарного потенціалу нелюдського інтелекту».
Найбільші компанії-розробники штучного інтелекту
Список компаній у сфері штучного інтелекту постійно зростає. Велика п’ятірка технологічних компаній Meta, Microsoft, Amazon, Apple і Google лідирує і у сфері штучного інтелекту. Проте на ринку з’являються й інші великі гравці.
| Компанія | Про компанію | Продукти |
|---|---|---|
| NVIDIA, США | Домінує на ринку чипів для ШІ. Капіталізація компанії на початку 2026 р. сягнула 2,7 трильйона доларів. Стратегічні інвестиції в суперкомп’ютери. | Чипи для ШІ. |
| Microsoft, США | Одна з найбільших у світі компаній з розробки програмного забезпечення, пристроїв та хмарних сервісів перетворилася на лідера в галузі ШІ як послуги. Його платформа Azure AI є комерційним двигуном цієї трансформації, а дохід від штучного інтелекту оцінюється в понад 42 мільярди доларів і швидко зростає. | Microsoft Cloud (Azure AI, Microsoft 365 та ін.) —комплексна екосистема хмарних рішень, що об’єднує інфраструктуру, платформи для розробки, інструменти для продуктивної роботи та безпеку в єдине ціле. Вона допомагає бізнесу та приватним користувачам зберігати дані, створювати застосунки та керувати ІТ-процесами з будь-якого куточка світу. |
| Apple, США | Проєктує та розробляє споживчу електроніку, програмне забезпечення та онлайн-сервіси. | Siri — інтелектуальний віртуальний асистент |
| Alphabet (Google), США | Материнська компанія Google. Дочірньою компанією є DeepMind — розробник ШІ. 17 лютого 2025 року суд у Росії оштрафував компанію Alphabet Inc. на $41530 за розміщення на платформі YouTube відео, що містило інструкції для російських військовослужбовців про те, як здатися у полон. | Gemini — велика мовна модель, яка працює за тим же принципом, що й ChatGPT: працює з текстом, генерує зображення, може працювати віртуальним помічником. Перевагою є те, що цей інструмент глибоко інтегрований із сервісами Google Workspace, а тому може аналізувати файли на Google Drive, листи у Gmail, а також планувати події у календарі. |
| Meta Platforms, США | Транснаціональна компанія, заснована Марком Цукербергом. Володіє Facebook, Instagram, WhatsApp, розробником шоломів віртуальної реальності Oculus VR. | Meta AI — це дослідницький підрозділ Meta (раніше Facebook), який розробляє штучний інтелект та технології доповненої реальності. Створила віртуального помічника з аналогічною назвою. |
| OpenAI, США | Провідна американська компанія та дослідницька лабораторія у сфері штучного інтелекту, заснована у 2015 році. Компанію оцінюють в 300 млрд доларів. | ChatGPT — найвідоміший чат-бот на основі великих мовних моделей, який здатен вести діалог, писати тексти, програмувати та аналізувати інформацію. Sora — генеративна модель для створення відео. |
| Anthropic, США | Заснована колишніми співробітниками OpenAI. Має статус корпорації суспільного блага (PBC). Це означає, що її головна мета — не лише отримання прибутку, а й принесення користі суспільству та розробка безпечного ШІ. Спеціалізується на створенні безпечних і етичних ШІ-систем. | Claude, що належить до сімейства великих мовних моделей і спеціалізується на глибокому аналізі тексту, здатна вирішувати складні аналітичні завдання. Має вбудовані етичні фільтри, що допомагають їй уникати шкідливого, неправдивого чи неетичного контенту. |
| Gamma, США | Американська кампанія зі штаб-квартирою у Сан-Франциско. На ринку конкурує з іншими кампаніями, як-от Canva та Adobe. | Gamma — популярний сервіс для створення презентацій, документів та вебсайтів за допомогою ШІ. |
| xAI (TruthGPT) | Компанія Ілона Маска, що займається штучним інтелектом, придбала X, гіганта соціальних мереж, раніше відомого як Twitter. Це дозволило інтегрувати можливості штучного інтелекту xAI з величезною базою користувачів X, покращуючи онлайн-взаємодію. | Grok — нейромережа, яка має знижений рівень обмежень, через що є доволі токсичною. Головна її відмінність — прямий доступ до стрічки новин і публікацій у реальному часі через соцмережу X (Twitter). |
| DeepSeek, Китай | Китайська компанія в галузі ШІ, що розробляє моделі з відкритим кодом. Прямий конкурент для розробників ChatGPT. | DeepSeek-R1: використовує механізми цензури для тем, які стосуються політики Китайської Народної Республіки. Наприклад, модель відмовляється відповідати на запитання про події на площі Тяньаньмень 1989 року, переслідування уйгурів або стан прав людини в Китаї. |
Україна та ШІ
Україна посідає друге місце за кількістю ШІ-компаній у Центральній та Східній Європі. За результатами дослідження, яке провели Міністерство цифрової трансформації спільно з найбільшим AI-ком’юніті України AI HOUSE та інвестиційною групою Roosh, протягом десяти років кількість AI-компаній виросла більш ніж удвічі — з 97 до 243 станом на кінець 2023 року. Порівняно з іншими європейськими країнами, Україна має вищу концентрацію AI-стартапів у сферах маркетингу, геймінгу та програмного забезпечення для бізнесу, оскільки українські експерти мають експертизу у цих галузях. Останні роки війна спонукала Україну активно інтегрувати ШІ у сфері оборони, і тепер ми можемо передавати цей досвід іншим країнам.
Зокрема, в Україні впроваджуються такі проєкти:
- Дія.АІ — персональний асистент у світі державних послуг. Він надає консультації щодо послуг, підбирає послуги під життєві ситуації, надає дані про бізнес і власність та багато іншого. Детальніше про те, як працює цей асистент, можна дізнатися на офіційному порталі.
- Українська національна велика мовна модель (LLM) «Сяйво», яку створює Мінцифри спільно з «Київстаром». Станом на 2026 рік триває процес пошуку даних для тренування моделі та експертів. Більше за посиланням: llm.thedigital.gov.ua
- Освітній застосунок «Мрія» — новий застосунок, який впроваджується у школах і має прибрати зайву бюрократію та допомагати вчителям навчати, створювати тести та завдання, а учням краще розуміти свої здібності. Застосунок можна завантажити за посиланням: mriia.gov.ua/app
- Малі мовні моделі під специфічні галузі. Мінцифри оголосило, що розпочало роботу над створенням малих мовних моделей, зокрема розробку та тестування моделей для ШІ в судах, що допомагатиме формувати проєкти судових рішень і прискорить розгляд справ для громадян.
Україна посідає 4-те місце за рівнем зрілості відкритих даних (Open Data Maturity) серед 36 країн Європи, Також важливо зазначити, що станом на початок 2026 року, за результатами дослідження Інституту економічних досліджень та політичних консультацій (ІЕД), прямий економічний ефект від використання публічної інформації сягнув 26,8 млрд гривень. Йдеться про дані із різних сфер.
Ключові набори даних в Україні такі:
- Єдиний державний реєстр юридичних осіб, фізичних осіб-підприємців та громадських формувань (ЄДР)
- Єдиний державний реєстр судових рішень та судові дані
- Податкові дані
- Фінансова звітність підприємств
- Дані публічних закупівель (Prozorro)
- Державний земельний кадастр та Національна інфраструктура геопросторових даних
- Дані НБУ та банківська статистика
- Дані про публічні фінанси (Є-дата)
- Митні дані
- Екологічні дані
- Освітні дані
- Дані з охорони здоров’я
Після того, як росія розпочала війну проти України та окупувала частину територій у 2014 році, а у 2022 році здійснила повномасштабне вторгнення, частину державних даних, зокрема реєстрів, було закрито з міркувань безпеки.
Відкриті дані, окрім використання для ухвалення рішень та інших функцій, дають основу для застосування ШІ та машинного навчання. А в аналітичному звіті «Ринок відкритих даних України: стан, динаміка та вплив» вказується на те, що на основі цих наборів даних українські компанії формують внутрішні API-модулі з машинним навчанням, які визначають поведінкові патерни клієнтів, прогнозують імовірність ризикових подій та моделюють кредитні, юридичні й комплаєнс-сценарії тощо. «Відкриті набори спрощують тестування алгоритмів штучного інтелекту, скорочують витрати на створення навчальних вибірок і прискорюють процес розробки. Таким чином, відкриті дані не лише забезпечують стабільність бізнес-моделей, а й слугують базою для технологічного прориву та конкурентної переваги українських ІТ-компаній», — зазначають автори звіту.
Негативний вплив ШІ на довкілля
Проте штучний інтелект — це не лише про розвиток та інновації. Це й також про негативний вплив на довкілля, споживання енергії, води та викиди.
Коли ви «розмовляєте» із ChatGPT або з будь-яким іншим ШІ-інструментом, пригадайте про те, що центри обробки даних потребують величезної кількості енергії, а також прісної води для охолодження, процес навчання однієї моделі штучного інтелекту, такої як LLM, може споживати тисячі мегават-годин електроенергії та викидати сотні тонн вуглецю, йдеться у дослідженні, опублікованому в Harvard Business Review. До прикладу, у 2025 році викиди від навчання Grok 4 були еквівалентні 72 816 тонн CO₂, а річне споживання води для роботи однієї з найбільших мовних моделей, таких як ChatGPT, може перевищити потреби 1,2 мільйона людей у питній воді.
Європейський Союз та США запровадили законодавство для пом’якшення впливу штучного інтелекту на довкілля. Але таких заходів замало. Міжнародні рекомендації для технологічних гігантів враховувати екологічні аспекти є необов’язковими та ніяк не розв’язують екологічні проблеми, які наростатимуть.
Що почитати
- 50 найперспективніших компаній, які будують бізнес на основі штучного інтелекту. Список Forbes-2025 (українською мовою). Forbes. 2023
- AI-екосистема України: Таланти, компанії, освіта. AI House. 2024
- Ринок відкритих даних України: стан, динаміка та вплив / І. Бураковський та ін. 2025
- Тартачний О. Штучний інтелект під загрозою: де техкомпанії братимуть дані для навчання. Speka. 2024
- Кіссинджер Г., Манді К., Шмідт Е. Генезис. Штучний інтелект, надія та людський дух / пер. І. Красіков. Київ : Stone Publishing, 2025. 224 с.
- Лі Кай-Фу. AI. Наддержави штучного інтелекту. Китай, Кремнієва долина і новий світовий лад / пер. В. Пунько. Київ : Book Chef, 2020. 240 с.
- Скіннер К. Людина цифрова. Четверта революція в історії людства, яка торкнеться кожного / пер. Г. Якубовська. Харків : Фабула, 2020. 272 с.
- Хан С. Слова чудові в світі новім. Як штучний інтелект зробить революцію в освіті (і чому це добре). / пер. А. Дудченко. Київ : Наш Формат, 2025. 240 с.
- Харарі Ю. Н. Nexus. Коротка історія інформаційних мереж від кам’яного віку до ШІ / пер. Н. Хаєцька. Київ : Book Chef, 2025. 640 с.
Що подивитися
«Метрополіс» (1927), режисер Фріц Ланґ
«Штучний розум» (2001), режисер Стівен Спілберг
«Я, Робот» (2004), режисер Алекс Пройас
«Робот та Френк» (2012), режисер Джейк Шреєр
«Гра в імітацію» (2014), режисер Мортен Тильдум
У стрічці йдеться про те, як під час Другої світової війни британська команда на чолі з математиком Аланом Тюрінгом намагається розшифрувати сигнал нацистської шифрувальної машини «Енігма». У головних ролях — Бенедикт Камбербетч та Кіра Найтлі.